
imgProc-ex4
实验四:手写数字识别
实验目的
-
掌握分类、识别问题的实质,了解各种分类问题的机器学习方法,并至少掌握一种,熟悉 Python 编程。
实验内容
-
对实验提供的手写数据库(MNIST)进行训练和测试,最终能够较为准确的识别数据库中的手写体数字。
实验要求
-
编写一完整的 Python 程序,选取一种合适的机器学习方法,对实验提供的手写数据库(MNIST)进行训练和测试,最终能够较为准确的识别数据库中的手写体数字。
-
运行训练程序,并通过 tensorboard 可视化,通过图片展示训练过程中的Loss 和测试准确度。并且测试最好模型的识别准确度。
实验原理
-
采用卷积神经网络(Convolutional Neural Networks, CNN)来实现实验要求。卷积神经网络由输入层,卷积层,池化层,全连接层,输出层等组成。输入层处理输入的图像数据,在卷积层经过二维卷积运算提取特征,在经过池化层对提取到的特征进行选择和过滤,最终通过全连接层经过梯度运算迭代结果。因此,在卷积神经网络中图形的特征可以自动提取,并不需要对所分类图形的处理具有先图像处理与信息隐藏课程实验验知识。
实验过程
-
Pytorch 环境配置
-
OS:macOS Sonoma 14.1
-
芯片:M1 PRO
-
python:3.10.8
-
pyCharm:2023.2
根据官网教程,直接使用pip进行安装
1
pip3 install torch torchvision
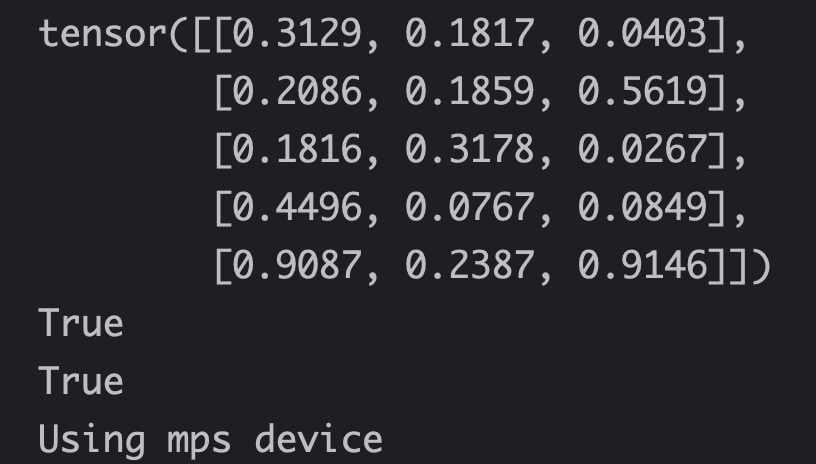
测试支持mac M1的GPU加速:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import torch
if __name__ == '__main__':
x = torch.rand(5, 3)
print(x)
# this ensures that the current MacOS version is at least 12.3+
print(torch.backends.mps.is_available())
# this ensures that the current PyTorch installation was built with MPS activated.
print(torch.backends.mps.is_built())
dtype = torch.float
device = (
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
print(f"Using {device} device")验证成功可以使用mps加速
-
-
代码分析
-
net.py:神经网络模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
# 第一个卷积层:输入通道数为 1(灰度图像),输出通道数为 32,卷积核大小为 3x3
self.conv1 = torch.nn.Sequential(
# 创建一个卷积层
torch.nn.Conv2d(1, 32, 3, 1, 1),
# 添加激活函数 ReLU
torch.nn.ReLU(),
# 添加最大池化层。这一层的作用是提取图像的特征并减小空间分辨率
torch.nn.MaxPool2d(2)
)
# 第二个卷积层:输入通道数为 32,输出通道数为 64,卷积核大小为 3x3
self.conv2 = torch.nn.Sequential(
torch.nn.Conv2d(32, 64, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2)
)
# 第三个卷积层:输入通道数为 64,输出通道数为 64,卷积核大小为 3x3
self.conv3 = torch.nn.Sequential(
torch.nn.Conv2d(64, 64, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2)
)
# 全连接层:输入大小为 64 * 3 * 3,输出大小为 128
self.dense = torch.nn.Sequential(
# 创建线性层,输入大小为 64 * 3 * 3,输出大小为 128
torch.nn.Linear(64 * 3 * 3, 128),
# 激活函数 ReLU
torch.nn.ReLU(),
# 通过另一个线性层输出大小为 10(假设这是一个分类问题)
torch.nn.Linear(128, 10)
)
def forward(self, x):
"""
定义网络的前向传播方法
:param x:
:return:
"""
# 通过每个卷积层和激活函数
conv1_out = self.conv1(x)
conv2_out = self.conv2(conv1_out)
conv3_out = self.conv3(conv2_out)
# 将输出展平成一维向量
res = conv3_out.view(conv3_out.size(0), -1)
# 通过全连接层
out = self.dense(res)
return out -
train.py:实现训练
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133# 验证是否能调用GPU训练
device = (
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
print(f"Using {device} device")
# 载入模型
model = Net().to(device)
# 学习率
lr = 0.01
print(model)
# 定义交叉熵损失函数用于多分类问题
loss_func = torch.nn.CrossEntropyLoss().to(device)
# 定义Adam优化器
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
def train_epoch(epoch, train_loader, train_data, model, train_optimizer, train_loss=0., train_acc=0.):
"""
周期训练函数
:param epoch: 训练周期
:param train_loader: 训练数据加载器
:param train_data: 训练数据集
:param model: 神经网络模型
:param train_optimizer: 训练优化器
:param train_loss: 训练损失
:param train_acc: 训练准确度
:return: 整个训练数据集上的平均训练损失
"""
iter = 0
# batch_x是图片, batch_y是标签
# 迭代训练数据加载器中的数据批次
for batch_x, batch_y in train_loader:
# 将数据批次移动到指定的设备上
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
# 通过神经网络模型传递数据批次以获取预测值 out
out = model(batch_x) # 64*1*28*28
# 使用指定的损失函数(loss_func)计算模型预测和实际标签之间的损失
loss = loss_func(out, batch_y)
# 更新训练损失的累加值
train_loss += loss.data.item()
# 通过选择指定维度上的最大值的索引(通常是类别维度),获取预测标签
pred = torch.max(out, 1)[1]
# 计算批次中正确预测的数量
train_correct = (pred == batch_y).sum()
# 更新准确度的累加值,用于后续计算准确
train_acc += train_correct.data.item()
# 执行反向传播以计算梯度,并使用优化器更新模型参数
train_optimizer.zero_grad()
loss.backward()
train_optimizer.step()
# 每100次迭代打印训练进度信息,包括当前周期、处理的样本数以及计算的损失和准确度
iter += 1
if iter % 100 == 0:
print(f'Train epoch {epoch}: ['
f'{iter * len(batch_y)}/{len(train_loader.dataset)}'
f' ({100. * iter * len(batch_y) / len(train_loader.dataset):.0f}%)]'
f'\tLoss: {train_loss / (iter * len(batch_y)):.6f}'
f'\tAccuracy: {train_acc / (iter * len(batch_y)):.6f}')
return train_loss / (len(train_data))
def test_epoch(epoch, test_loader, test_data, model, eval_loss=0., eval_acc=0.):
"""
在测试集上评估神经网络模型性能
:param epoch: 测试周期
:param test_loader: 测试数据加载器
:param test_data: 测试数据集
:param model: 神经网络模型
:param eval_loss: 测试损失
:param eval_acc: 测试准确度
:return: 整个测试数据集上的平均测试准确度。
"""
# 将模型设置为评估模式
model.eval()
# 上下文管理器。确保在该上下文中不会进行梯度计算。这是因为在测试过程中,我们只关心模型的推断结果,不需要计算梯度。
with torch.no_grad():
# 迭代测试数据加载器中的数据批次
for batch_x, batch_y in test_loader:
# 将数据批次移动到指定的设备上
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
# 通过神经网络模型传递数据批次以获取预测值
out = model(batch_x)
# 使用指定的损失函数计算模型预测和实际标签之间的损失
loss = loss_func(out, batch_y)
# 更新测试损失的累加值
eval_loss += loss.data.item()
# 通过选择指定维度上的最大值的索引,获取预测标签
pred = torch.max(out, 1)[1]
# 计算批次中正确预测的数量
num_correct = (pred == batch_y).sum()
# 更新准确度的累加值
eval_acc += num_correct.data.item()
# 打印测试结果,包括当前测试周期、平均测试损失和平均测试准确度
print(f'\nTest epoch {epoch}: '
f'\tAverageLoss: {eval_loss / (len(test_data)):.6f}'
f'\tAverageAccuracy: {eval_acc / (len(test_data)):.6f}\n')
# 这个返回值可以用来评估模型在测试数据上的性能
return eval_acc / (len(test_data))
def main():
best_accu = 1e-10
# 数据集定义,没有会自动下载
train_data = torchvision.datasets.MNIST(
'./mnist', train=True, transform=torchvision.transforms.ToTensor(), download=True
)
test_data = torchvision.datasets.MNIST(
'./mnist', train=False, transform=torchvision.transforms.ToTensor()
)
print("train_data:", train_data.train_data.size())
print("train_labels:", train_data.train_labels.size())
print("test_data:", test_data.test_data.size())
# 定义dataloader
# 定义batch size为64,即每个元素在定义的可迭代dataloader中,将返回一批 64 个特征和标签。
train_loader = Data.DataLoader(dataset=train_data, batch_size=64, shuffle=True)
test_loader = Data.DataLoader(dataset=test_data, batch_size=64)
# 定义tensorboard可视化
writer = SummaryWriter('./boardlog')
for epoch in range(80):
train_loss = train_epoch(epoch, train_loader, train_data, model, optimizer)
accu = test_epoch(epoch, test_loader, test_data, model)
# 记录train loss和测试集上的识别准确度
writer.add_scalar('train_loss', train_loss, global_step=epoch, walltime=None)
writer.add_scalar('val_loss', accu, global_step=epoch, walltime=None)
if accu > best_accu:
# 保存最佳模型及参数
best_accu = accu
print("This epoch trained the best loss")
torch.save(model, f'net.pth') -
test.py:进行独立测试
-
代码分析与训练测试类似,不再赘述
-
测试结果如下(Using mps device):

-
测试结果可视化如下:

-
-
-
Tensorboard 的可视化
-
安装tensorboard
1
pip3 install tensorboard
-
启动tensorboard
1
tensorboard --logdir='boardlog'
-
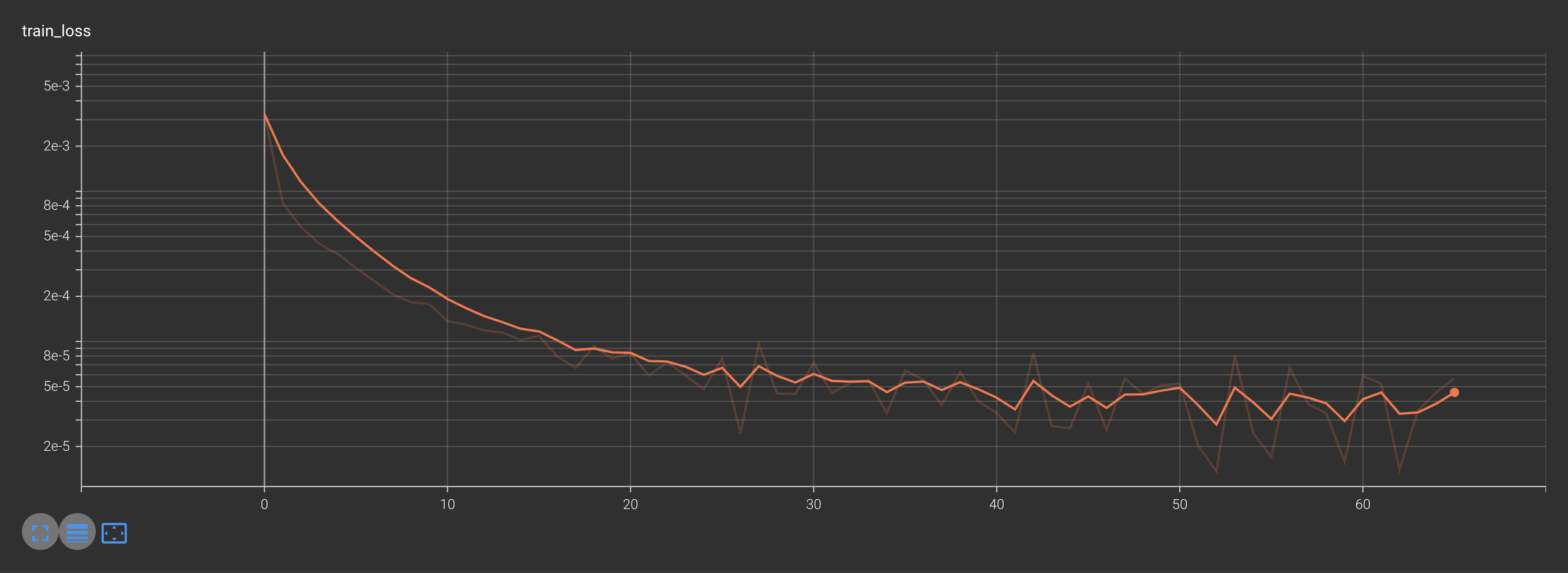
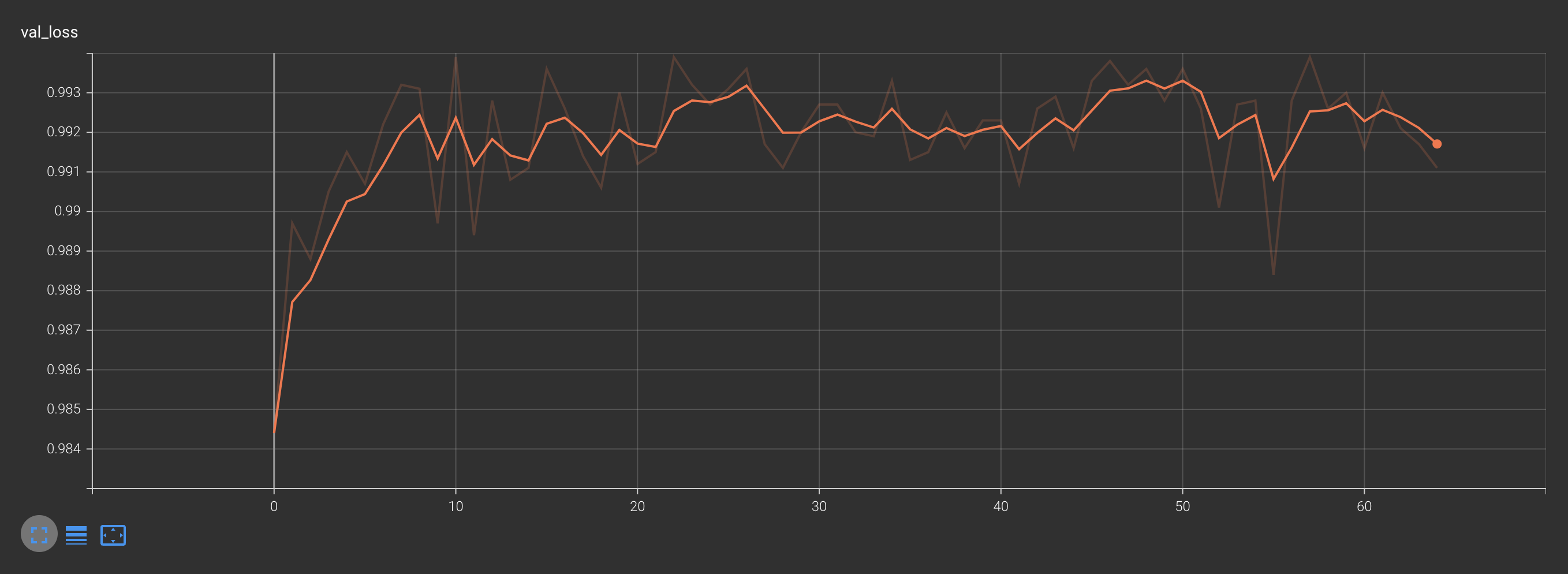
可视化结果如下:
-
训练损失
-
训练中测试的损失
-
-
-
可以通过修改网络结构、修改学习率、损失函数、优化器、batchsize 来提升识别精度。
-
网络结构助教给出的已经相对复杂,故不再修改
-
常用的损失函数包括
交叉熵损失函数和均方误差损失函数-
叉熵损失函数适用于多分类问题,特别是分类任务。
-
对于手写数字识别,通常输出是对每个数字类别的概率分布,交叉熵损失能够衡量实际分布与预测分布之间的差异。
-
助教给出的代码使用 torch.nn.CrossEntropyLoss 实现,不再修改
-
-
常用的优化器包括随机梯度下降(SGD)、Adam、和RMSprop
-
随机梯度下降 (SGD):
- 基本的优化算法,通过计算梯度并沿梯度方向更新参数。
- 在某些情况下,可能需要手动调整学习率。
-
Adam:
- 自适应矩估计(Adaptive Moment Estimation)的缩写,结合了动量项和自适应学习率。
- 适用于很多任务,通常表现良好,无需手动调整学习率。
-
RMSprop:
- Root Mean Square Propagation 的缩写,也是一种自适应学习率的优化算法。
- 在某些情况下,对于非平稳目标函数可能表现更好。
-
通常而言,Adam 是一个比较常用的默认选择,因为它在很多任务中都能够取得不错的效果,并且无需过多的调参,故不在修改。
-
-
batch size:目的让模型在训练过程中每次选择批量的数据来进行处理。
-
batch Size的直观理解就是一次训练所选取的样本数。
-
batch size的设置通常10到100,一般设置为2的n次方,故仍选用64进行实验
-
-
尝试使用学习率调度器,动态调整学习率进行加速收敛
1
2
3
4lr = 0.01
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
# StepLR 是一个简单的学习率调度器,每 step_size 个epoch,学习率降低 gamma 倍
scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.66) -
经过5-6次左右调参数,如调整学习率初始值
lr、step_size和gamma后,效果始终不理想- 在总轮数设置为60左右,可以在40轮左右时达到98.5%以上的准确率,但是后续并不会进一步优化,而且加速效果不明显
- 由于一次需跑15min左右… …后续未再进行测试,如果有时间可以继续研究一下。。。
- 询问助教得知可能跟初始学习率有关,有可能到达了局部最优点
-
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 lzhのBLOG!



